
Introduction
With the uninterrupted growth of data volumes ever since the primitive ages of computing, storage of information, support and maintenance has been the biggest challenge. Also, the cloud computing technology has positioned a new dimension ("pay-as-you-go" model) to the information storage with efficient use of computer resources. Even the matured relational database products in the current market fall behind to scaling the applications according to the incoming traffic at a conventional cost. The demands of huge data and elastic scaling with desired performance has led to concept of No SQL databases. No SQL - undoubtedly is the hottest stint in today’s database technology and moving the data from the existing data structures to No SQL would be the potential area of interest for the customers.
What are No SQL Databases
No SQL databases are the data stores that are non-relational (without any fixed schemas & joins), distributed, horizontally scalable and often don’t adhere to the principles (ACID: atomicity, consistency, isolation, durability) of traditional relational databases.
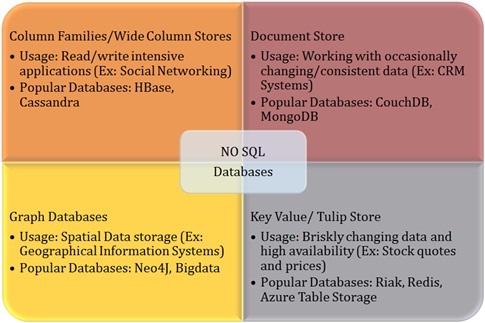
- Column family (Wide column) stores
- Graph databases
- Key value/tulip store
- Document stores
| Product | Details |
| Cassandra | Latest Version: V 0.8.6 License: Apache Protocol: Custom, binary (Thrift) API: Java/ Any Writer |
| HBase | Latest Version: V 0.90.3 License: Apache Protocol: HTTP/REST API: Thrift |
| MongoDB | Latest Version: V 2.0.0 License: Affero General Public License (AGPL) Protocol: Custom, Binary API: BSON |
| CouchDB | Latest Version: V 1.1.0 License: Apache Protocol: HTTP/REST API: JSON |
| Neo4J | Latest Version: V 1.5.M01 License: AGPL/commercial Protocol: HTTP/REST API: Java Embedded |
| Riak | Latest Version: V 1.0.0 License: Apache Protocol: HTTP/REST or custom binary API: JSON |
| Redis | Latest Version: V 2.2.14 License: Berkeley Software Distribution (BSD) Protocol: Telnet-Like API: Wide Spread Languages |
| Membase | Latest Version: V 1.7 License: Apache Protocol: Memcached REST interface for cluster conf + management API: JSON |
What is JSON
JSON (stands for JavaScript Object Notation) is a lightweight and highly portable data-interchange format. JSON is intuitive to the web as well as the browser. Interoperability with any/all platforms in the current market can be easily achieved using JSON message format.
According to JSON.org (www.json.org):
“JSON is built on two structures:
· A collection of name/value pairs. In various languages, this is realized as an object, record, dictionary, structure, keyed list, hash table or associative array.
· An ordered list of values. In most languages, this is realized as an array, list, vector, or sequence.
These are universal data structures. Virtually all modern programming languages support them in one form or another. It makes sense that a data format that is interchangeable with programming languages also be based on these structures.”
A typical JSON syntax is as follows:
- Data is represented in the form of name-value pairs.
- A name value pair is comprised of a “Member Name” in double quotes, followed by colon “:” and the value in double quotes
- Each data member (Name-Value pair) is separated by comma
- Objects are held with-in curly (“{ }”) brackets.
- Arrays are held with-in square (“[ ]”) brackets.
JSON Example:
{"Author":
{
"First Name": "Phani Krishna",
"Last Name": "Kollapur Gandla",
"Contact": {
"URL": “in.linkedin.com/in/phanikrishnakollapurgandla",
"Mail ID": "<a href="mailto:phanikrishna_gandla@xyz.com">phanikrishna_gandla@xyz.com</a>"}
}
}JSON and XML JSON is significantly like XML:
• JSON is plain text data formatJSON vs. XML
• JSON is human readable and self-describing
• JSON is categorized (contains values within values)
• JSON can be parsed by scripting languages like Java script
• JSON data is supported and transported using AJAX
Though JSON & XML are both data formats, JSON has the upper hand over XML because of the following reasons:
• JSON is lighter compared to XML (No unnecessary/additional tags in JSON)Several No SQL products have provided built-in capabilities/readily available tools for loading data from JSON file format. Below is the list of import/export utilities for some of the widely held No SQL products
• JSON is easier to read and understand by humans.
• JSON is easier to parse and generate for machines.
• For AJAX related applications, JSON is quite faster compared to XML
| Product | Import/Export Utilities for JSON |
| Cassandra | json2sstable -> JSON to Cassandra data structure sstable2JSON -> Cassandra data structure to JSON |
| MongoDB | mongoimport -> JSON/CSV/TSV to MongoDB data structure mongoexport -> MongoDB data structure to JSON/CSV |
| CouchDB | tools/load.py-> JSON to CouchDB data structure tools/dump.py -> CouchDB data structure to JSON |
| Riak | bucket_importer:import_data-> JSON to Riak data structure bucket_exporter:EXport_data -> Riak data structure to JSON |
Cassandra Data Model
Understanding Cassandra data model
The Cassandra data model is premeditated for highly distributed and large scale data. It trades off the customary database guidelines (ACID compliant) for important benefits in operational manageability, performance and availability.
An illustration of how a Cassandra data model would like is as below:
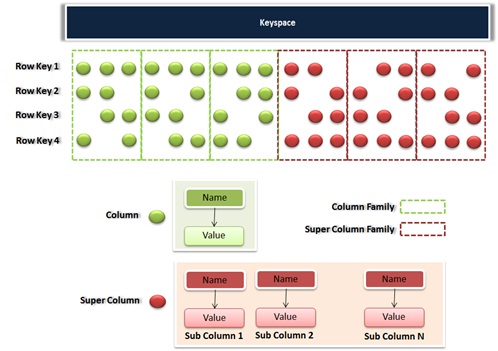
The basic elements of the Cassandra data model are as follows:
• Column
• Super Column
• Column Family
• Keyspace
• Cluster
Column: A column is the basic unit of Cassandra data model. A column comprises of name, value and a time stamp (by default). An example of column in JSON format is as follows:
{ // Example of Column
"name": "EmployeeID",
"value": "01234",
"timestamp": 123456789
} Super Column: A Super column is a dictionary of boundless number of columns, identified by the column name. An example of super column in JSON format is as follows:
{ // Example of Super Column
"name": "designation",
"value": {
"role" : {"name": "role", "value": "Architect", "timestamp": 123456789},
"band" : {"name": "band", "value": "6A", "timestamp": 123456789}
} The major differences between a column and a super column are:
• Column’s value is a string but the super column’s value is a record of columns
• A super column doesn’t include any time stamp (only terms name & value).
Note: Cassandra does not index sub columns, so when a super column is loaded into memory; all of its columns are loaded as well.
Column Family (CF): A column family resembles an RDBMS table closely and is an assembly of ordered collection of rows which in-turn are ordered collection of columns. A column family can be a “standard” or a “super” column family.
A row in a standard column family contains collections of name/value pairs whereas the row in a super column family(SCF) holds collections of super columns (group of sub columns). An example for a column family is described below (in JSON):
Employee = { // Employee Column Family
"01234" : { // Row key for Employee ID - 01234
// Collection of name value pairs
"EmpName" : "Jack",
"mail" : "<a href="mailto:Jack@xyz.com">Jack@xyz.com</a>",
"phone" : "9999900000"
//There can be N number of columns
},
"01235" : { // Row key for Employee ID - 01235
// Collection of name value pairs
"EmpName" : "Jill",
"mail" : "<a href="mailto:Jill@xyz.com">Jill@xyz.com</a>",
"phone" : "9090909090"
"VOIP" : "0404787829022",
"OnsiteMail" : "<a href="mailto:jackandjill@abcdef.com">jackandjill@abcdef.com</a>"
},
}Note: Each column would contain “Time Stamp” by default. For easier narration, time stamp is not included here.
The address of a value in a regular column family is a row key pointing to a column name pointing to a value, while the address of a value in a column family of type “super” is a row key pointing to a column name pointing to a sub column name pointing to a value. An example for Super column in JSON format is as follows:
ProjectsExecuted = { // Super column family
"01234" : { // Row key for Employee ID - 01235
//Projects executed by the employee with ID - 01234
"project1" : {"projcode" : "proj1", "start": "01012011", "end": "03082011", "location": "hyderabad"},
"project2" : {"projcode" : "proj2", "start": "01042010", "end": "12122010", "location": "chennai"},
"project3" : {"projcode" : "proj3", "start": "06062009", "end": "01012010", "location": "singapore"}
//There can be N number of super columns
},
"01235" : { // Row key for Employee ID - 01235
//Projects executed by the employee with ID - 01235
"projXYZ" : {"projcode" : "Cod1", "start": "01012011", "end": "03082011", "location": "bangalore"},
"proj123" : {"projcode" : "Cod2", "start": "01042010", "end": "12122010", "location": "mumbai"},
},
}Columns are always organized as per the Column‘s name within their rows. The data would be sorted as soon as it is inserted into the data model.
Keyspace: A keyspace is the outmost grouping for data in Cassandra, closely resembling an RDBMS database. Similar to the relational database, a keyspace has title and properties that describe the keyspace demeanor. The keyspace is a container for a list of one or more column families (without any enforced association between them).
Cluster: Cluster is the outermost structure in Cassandra (also called as ring). Cassandra database is specially designed to be spread across several machines functioning together that act as a single occurrence to the end user. Cassandra allocates data to nodes in the cluster by arranging them in a ring.
Relational data model vs. Cassandra data model
| Relational Data Model | Cassandra data model (Standard) | Cassandra data model (Super) |
| Server | Cluster | |
| Database | Key space | |
| Table | Column Family | |
| Primary Key | Key | |
| Column Value | Column Name | Super Column Name |
| | Column Value | Column Name |
| | | Column Value |
Unlike the traditional RDBMS, Cassandra doesn’t support
- Query language like SQL (T-SQL, PL/SQL etc.). Cassandra provides an API called thrift through which the data could be accessed.
- Referential Integrity (operations like cascading deletes are not available)
Designing Cassandra data structures
1. Entities – Point of Interest
The finest way to model a Cassandra data structure is to identify the entities on which most queries would be attentive and creating the entire structure around the entity. The activities performed (generally the use cases) by the user applications, how the data is retrieved and displayed would be the areas of interest for designing the Cassandra column families.
For example, a simple employee data model (in any RDMBS) would contain:
· Employee
· Employee contact details
· Employee financial information
· Employee role information
· Employee attendance information
· Employee projects
….
And so on…
Here “Employee” is the entity for point of interest and any application using this design would frame the queries relating to the employee.

2. De-normalization
Normalization is the set of rules established to aid in the design of tables and their relation-ships in any RDBMS. The benefits of normalizing would be:
• Avoiding repetitive entries
• Reduction of storage space required
• Prevention of schema restructuring for future needs.
• Improved speed and flexibility of SQL queries, joins, sorts, and search results.
Achieving the similar kind of performance for the growing data volume is a challenge in traditional relational data models and the companies could compromise on de-normalization to achieve performance. Cassandra does not support foreign key relationships like a relational database and the better way is to de-normalize the data model. The important fact is that instead of modeling the data first and framing the queries, with Cassandra the queries would be modeled and the data be framed around them.
3. Planning for Concurrent Writes
In Cassandra, every row within a column family is identified by the unique row key (generally a string of unlimited length). Unlike the traditional RDBMS primary key (which enforces uniqueness), Cassandra doesn’t impose uniqueness (Duplicate row key insertion might disturb the existing column structure). So the care must be taken to create the rows with unique row keys. Some of the ways for creating unique row keys is as follows:
• Surrogate/ UUID type of row keys
• Natural row keys
Data Migration approach (Using ETL)
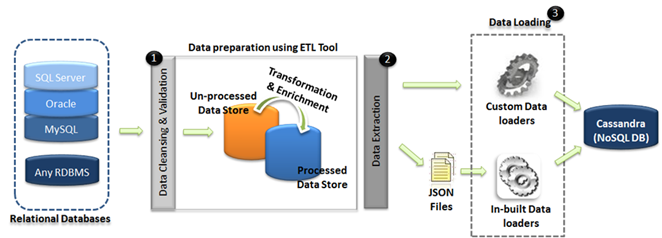
There are various ways of porting the data from relational data structures to Cassandra structures, but the migrations involving complex transformations and business validations might accommodate a data processing layer comprising ETL utilities.
In case of using in-built data loaders, the processed data can be extracted to flat files (in JSON format) and then uploaded to the Cassandra data structure’s using these loaders. Custom loaders could be fabricated in case of additional dispensation rules, which could either deal the data from the processed store or the JSON files.
The overall migration approach would be as follows:
- Data preparation as per the JSON file format.
- Data extractions into flat files as per the JSON file format or extraction of data from the processed data store using custom data loaders.
- Data loading using in-built or custom loaders into Cassandra data structure (s).
The various activities for all the different stages in migration are further discussed in detail in below sections.
Data Preparation and Extraction
- ETL is the standard process for data extraction, transformation and loading
- At the end of the ETL process, reconciliation forms an important part. This comprises validation of data with the business processes.
- The ETL process also involves the validation and enrichment of the data before loading into staging tables.

Data Preparation Activities:
The following activities will be executed during data preparation:
Data Extraction Activities (into JSON files):
The following activities will be executed during data extraction into JSON file formats:
Data Loading
Cassandra data structures can be accessed using different programing languages like (.net, Java, Python, Ruby etc.). Data can be directly loaded from the relational databases (like Access, SQL Server, Oracle, MySQL, IBM DB2, etc.) using these programing languages. Custom loaders could be used to load data into Cassandra data structure(s) based on the enactment rules, customization level and the kind of data processing.
References
- No SQL Databases (http://nosql-database.org/ )
- What is JSON (www.json.org )
- Migrating data from MS Access to Cassandra (http://www.divconq.com/2010/migrate-a-relational-database-structure-into-a-nosql-cassandra-structure-part-ii-northwind-planning/ )
- Cassandra column families (http://arin.me/blog/wtf-is-a-supercolumn-cassandra-data-model )
- Getting started with Cassandra (http://wiki.apache.org/cassandra/GettingStarted )
- JSON Tutorial (http://www.w3schools.com/json/default.asp)
No comments :
Post a Comment