
SQL Query Optimization FAQ Part 1 (The SQL Plan)
1) Introduction and Goal
2) What is a SQL execution Plan?
3) Can we understand step by step how SQL Query plan is created and executed?
4) Ok, so where do I start from?
5) What is a Table Scan (Operator number 1)?
6) Can performance increase by adding a unique key for table scans?
7) What are physical and logical reads?
8) Table scan doesn’t look to be efficient?
9) What is a seek scan (Operator number 2)?
10) Can we see a seek scan practically?
11) What are heap tables in SQL Server?
12) What is RID Lookup heap in SQL query plan?(Operator Number 3)
13) What is a bookmark lookup?
14) Lookups are costly operation, how can we eliminate the same?
15) What are covering indexes?
16) Do we have any other efficient way of creating covering indexes?
17) How does size of the index affect performance?
18) How does unique column increase index performance?
19) How important is the order of indexes?
20) What is the preferred data type for indexes?
21) What are indexed views and how does it improve performance?
22) Can we see practically how indexed views increase performance?
23) How do we specify index hints?
24) Does index hints increase performance?
25) References
Introduction and Goal
In this article we will first try to understand what is a SQL plan, how is it created and then we will move towards understanding how to read the SQL plan. As we read the SQL plan we will try to understand different operators like table scan, index seek scan, clustered scan, RID lookup etc. We will also look in to the best practices associated with clustered and non-clustered indexes and how they function internally. We will practically see how indexed views increase performance and in what scenarios we should use the same. Here’s my small gift for all my .NET friends, a complete 400 pages FAQ Ebook which covers various .NET technologies like Azure, WCF, WWF, Silverlight, WPF, SharePoint and lots more from here
Quick video to jump start SQL Server performance tuning
| Video description | Youtube Link |
| How SQL Server tuning wizard helps for performance tuning | http://youtu.be/AaPaIVI-yyI?hd=1 |
| SQL plan Concepts Iterators and logical reads | http://youtu.be/tWDM6PAA0S0 |
| How table scan performance is improve by creating unique keys | http://youtu.be/P9nnYPdJ-78?hd=1 |
What is a SQL execution Plan?
Every SQL query is broken down in to series of execution steps called as operators. Each operator performs basic operations like insertion, search, scan, updation, aggregation etc. There are 2 kinds of operators Logical operators and physical operators.Logical operators describe how the execution will be executed at a conceptual level while physical operators are the actual logic / routine which perform the action.

On the query plan you always physical operators. One logical operator can map to multiple physical operator. It can also go vice versa but that’s a rare scenario. Some operators are both physical as well as logical. You can check out all the logical and physical operators for SQL Server at http://msdn.microsoft.com/en-us/library/ms191158.aspx . Below table shows some sample mapping between logical and physical operators.
| Logical Operator | Physical operator |
| Inner join | • Merge join • Nested loops |
| Compute scalar | Compute scalar |
Can we understand step by step how SQL Query plan is created and executed?
There are three phases through which a SQL is parsed and executed.
Parse: - The first phase is to parse the SQL query for syntaxes and create a query processor tree which defines logical steps to execute the SQL. This process is also called as ‘algebrizer’.
Optimize: - The next step is to find a optimized way of executing the query processor tree defined by the ‘algebrizer’. This task is done by using ‘Optimizer’.’Optimizer’ takes data statistics like how many rows, how many unique data exist in the rows, do the table span over more than one page etc. In other words it takes information about data’s data. These all statistics are taken, the query processor tree is taken and a cost based plan is prepared using resources, CPU and I/O. The optimizer generates and evaluates many plan using the data statistics, query processor tree, CPU cost, I/O cost etc to choose the best plan.
The optimizer arrives to an estimated plan, for this estimated plan it tries to find an actual execution plan in the cache. Estimated plan is basically which comes out from the optimizer and actual plan is the one which is generated once the query is actually executed.
Execute: - The final step is to execute the plan which is sent by the optimizer.
Ok, so where do I start from?
Till now we have understood operators and the way SQL plan is created and executed. So the first thing is to understand different operators and their logic. As discussed previously operator’s form the basic unit of you SQL plan, if we are able to understand them we can optimize our SQL to a great extent. So let’s understand the basic and important operators.What is a Table Scan (Operator number 1)?
Before we try to understand table scan operator let’s try to see how can we see a SQL plan. Once you are in your SQL management studio, click on new query and write the SQL for which you want to see the SQL plan. Click on the icon which is displayed on the query window as shown below. Once you hit the icon you will see the query plan.
Now that we have understood how to see a query plan let try to understand the first basic operator i.e. table scan. In order to understand the same we have created a simple companies table with company code and description. Do not create any primary key or indexes. Now write a simple SQL with a select clause on one of the properties, we have selected company code currently as shown in the above figure.
If you hit on the query plan icon you will see table scan in your query plan. Now let’s try to understand what it signifies.

If there is a primary key table scan operator scans row by row every record until it finds the exact record. For instance in our search criteria we have given ‘500019’ as the company code. In table scan it goes row by row until it finds the record. Once it gets the record it sends the same as output to the end client.
In case the table does not have a primary key, it will continue searching ahead to find more matches if there are any.
Can performance increase by adding a unique key for table scans?
Yes, the performance increases if you add a unique key for table scan search criteria. Let’s see an actual demonstration of the same. So right click on the table field and create a unique key on customer code field as shown in the below figure.
Now let’s go to SQL Server analyzer and set the statistics to ‘ON’ using ‘set statistics io on’. With the statistics we also execute our query with the customer code criteria as shown in the below code snippet.
set statistics io on
SELECT TOP 1000 [CustomerCode]
,[CustomerName]
FROM [CustomerNew].[dbo].[Customers]
where customercode=524412
If you click on messages you will see logical reads as ‘3’.
(1 row(s) affected) Table 'Customers'. Scan count 0, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Now let’s go and remove the unique key the logical reads are 17, which means performance has degraded as compared with unique key.
(1 row(s) affected) Table 'Customers'. Scan count 1, logical reads 17, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
What are physical and logical reads?
The main work of database is to store and retrieve data. In other words lot of reads and writes to the disk. Read and writes consume lot of resources and take long time for completion. SQL server allocates virtual memory for cache to speed up I/O operations. Every instance of SQL server has its own cache.When data is read it is stored in the SQL cache until it’s not referenced or the cache is needed for some purpose. So rather than reading from physical disk its read from SQL cache. In the same way for writing, data is written back to disk only if it’s modified.

So when data is fetched from SQL cache its terms as logical read and when its read from physical database its termed as physical read.
Table scan doesn’t look to be efficient?
Table scan operators are good if the numbers of records in the tables are less. If the numbers of records in the tables are more, then table scan is very inefficient as it needs to scan row by row to get to the record.So for big number of rows in a table rather than table scan operator, seek scan operator is preferred.
What is a seek scan (Operator number 2)?
Seek scan does not scan all the rows to go to a record, it uses indexes and b-tree logic to get to a record. Below is a sample diagram, which explains how B-Tree fundamental works. The below diagram shows how index will work for number from 1-50:- • Let us say you want to search 39. SQL Server will first start from the first node i.e. root node.
• It will see that the number is greater than 30, so it moves to the 50 node.
• Further in Non-Leaf nodes it compares is it more than 40 or less than 40. As it’s less than 40 it loops through the leaf nodes which belong to 40 nodes.
In table scan it scans all rows while in seek scan it scans less number of rows comparatively. For instance to get to the record 39 it only scanned 9 records rather than travelling through all 50 records.

Can we see a seek scan practically?
On the same above sample lets create a clustered index on the company code field and see the SQL plan again by hitting the SQL plan icon.
If you view the SQL plan for the select query with company code you will see a clustered index seek operator as shown in the below figure. In other words it says that it will use b-tree logic for searching rather than traversing row by row.

In case you have a non-clustered index on the company code it will show a non-clustered index operator as shown below. You may be wondering what the RID lookup and nested loop is in the query plan, we will come to that later on.
The below figure indicates that its using the non-clustered index logical operator.

What are heap tables in SQL Server?
A table with no clustered indexes is termed as heap tables. The data rows of a heap table are not sorted, due to this there is a huge overhead of accessing heap tables.What is RID Lookup heap in SQL query plan?(Operator Number 3)
RID lookup will be seen when you use non-clustered indexes with join queries. For instance below is a simple join with customer and address table on ‘custcode’.SELECT Customers.CustomerName, Address.Address1 FROM Address INNER JOIN Customers ON Address.Custcode_fk = Customers.CustomerCode
If you do not put indexes on the primary table i.e. customer at this moment and you see the SQL plan, you should see the RID lookup heap as shown below. We will understand what it means, just try to get a glimpse of this operator first.

In order to understand the RID look up we need to first understand how non-clustered indexes work with clustered indexes and heap tables. Below is a simple figure which describes the working and their relationships.

Non-clustered indexes also use the B-tree structure fundamental to search data. In non-clustered indexes the leaf node is a ‘Rowid’ which points to different things depending on two scenarios:-
Scenario 1:- If the table which is having the primary key in the join has a clustered index on the join key (currently the join key is the custcode) then the leaf nodes i.e. ‘rowid’ will point to the index key of clustered index as shown below.

Scenario 2 :- if the table which is having the primary does not have a clustered index then the non-clustered index leaf node ‘rowid’ will point to actual row on the heap table. As the data is stored in a different heap table, it uses the lookup (i.e. RID lookup) to get to the actual row. Below is a query plan which has a join without clustered indexes.

What is a bookmark lookup?
As discussed in the previous section, when query searches on a column which is not a part of non-clustered index a lookup is required. As mentioned earlier either you need to lookup on the clustered index or you need to lookup on the heap tables i.e. RID lookup.The old definition for these lookup was called as ‘Bookmark’ look up. If you are seeing SQL plan using SQL 2000 you should see a bookmark lookup in your query plan. In SQL 2000 bookmark loop up used a dedicated iterator to determine whether the table is heap table or index table and change the search logic accordingly.
So cutting short index lookup and RID lookup are nothing but types of bookmark lookup.
Lookups are costly operation, how can we eliminate the same?
Yes, lookups are costly operations and should be avoided as far as possible. To avoid RID lookup or clustered lookup we can use covering indexes.Below is a simple table which has two fields customer code and customer name. Clustered indexes are defined on Customer code and non-clustered index is defined on customer name as shown in the table figure below.
| Indexes | Field name |
| Clustered index | Customer code |
| Non-clustered indexes | Customer name |
SELECT * FROM [CustomerNew].[dbo].[Customers] where CustomerName='20 microns'
As the non-clustered index needs to do a lookup on the clustered index it uses the RID lookup to get the clustered index. This lookup happens because the customer name non-clustered index does not have information about the clustered index data. If somehow we are able to make aware of clustered index data to non-clustered index the RID lookup can be avoided.

In order that the non-clustered index i.e. customer name is aware of the clustered index i.e. customer code we can create a combined non-clustered index on customer and customer doe as shown in the below figure.
| Indexes | Field name |
| Clustered index | Customer code |
| Non-clustered indexes | Customer name Customer code |
Now if you generate the plan you can see that RID lookup is completely eliminated. The customer code key in this current scenario is called as the covering index.

What are covering indexes?
As explained above. It helps to remove the lookup operation.Do we have any other efficient way of creating covering indexes?
The composite non-clustered index creation has certain draw backs:-• You cannot create composite indexes on data types like varchar(max) , XML.
• Size of the index increases the key size which further impacts performance.
• Can exceed the constraint of index key size of 900 bytes.
The best practice for creating covering index is by using the include keyword. So you create the non-clustered index as shown in the below code snippet.
You can see that we have included the customer code primary key as the part of our non-clustered index customer name and when you re-run the plan you can see how book mark lookup is removed and clustered indexes are used.
CREATE NONCLUSTERED INDEX [MyIndex] ON [dbo].[Customers] ( CustomerName ) INCLUDE (CustomerCode) ON [PRIMARY]
How does size of the index affect performance?
Let us make a statement before we answer this question:- ‘The more the size of the index key, performance will also degrade accordingly’. Let’s do a small practical example to understand the impact of the same. Below is a simple customer table with customer code and customer name field and below are the data types as shown in table.* Please note that customer code has a clustered index and the data type is int.
| Field name | Data type |
| Customer code ( Clustered index) | int |
| Customer name | Varchar(50) |
Just to revise people who are new SQL Server pages. Pages are fundamental unit of storage. In other words the disk space allocated on the hard disk is divided in to pages. A page size is normally of 8 kb. Page has data rows of SQL Server. If you can fit your rows in one page you do not need to jump from on page to other page, which increases performance.

Now if you fire the below SQL statement it will give you number of pages consumed to store the clustered index. You can see from the results below clustered index with ‘int’ uses 12 pages.
SELECT Indextable.Name
,Indextable.type_desc
,PhysicalStat.page_count
,PhysicalStat.record_count
,PhysicalStat.index_level
FROM sys.indexes Indextable
JOIN sys.dm_db_index_physical_stats(DB_ID(N'Customer'),
OBJECT_ID(N'dbo.CustomerTable'),NULL, NULL, 'DETAILED') AS PhysicalStat
ON Indextable.index_id = PhysicalStat.index_id
WHERE Indextable.OBJECT_ID = OBJECT_ID(N'dbo.CustomerTable')
| Name | type_desc | page_count | record_count | index_level |
| IX_Customers | CLUSTERED | 12 | 3025 | 0 |
| IX_Customers | CLUSTERED | 1 | 12 | 1 |
| Field name | Data type |
| Customer code ( Clustered index) | numeric |
| Customer name | Varchar(50) |
| Name | type_desc | page_count | record_count | index_level |
| IX_Customers | CLUSTERED | 14 | 3025 | 0 |
| IX_Customers | CLUSTERED | 1 | 14 | 1 |

So concluding the more the size of the index, the more the number of pages and worse the performance. Avoid data types like ‘char’ , ‘varchar’ , ‘int’ is the preferred data type for indexes.
If the clustered indexes are small we get the following advantages:-
- Reduces I/O as the number of 8 KB page decrease.
- As the size decreases caching size is increased.
- Less storage space required.
How does unique column increase index performance?
Creating indexes on unique column values increases performance of indexes. So unique columns always are best candidates for clustered indexes. Let’s demonstrate how creating clustered indexes on unique columns increases performances as compared to creating indexes on columns with non-unique values.Below is a simple query which is fired on the customer table which has two fields ‘active’ and ‘customercode’. ‘customercode’ field has unique values while ‘active’ field has non-unique values , it has only two values ‘1’ and ‘0’. Below is a SQL statement which is fired with statistics IO ON.
set statistics io on SELECT * FROM Customers where active=1 and CustomerCode=500008If you fire the above statement with clustered index on ‘customercode’ field the logical reads are ‘2’.
(1 row(s) affected) Table 'Customers'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.If you fire the above SQL statement with clustered index on ‘active’ field the logical reads are 16. In other words the performance is hampered.
(1 row(s) affected) Table 'Customers'. Scan count 1, logical reads 16, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
How important is the order of indexes?
When you create composite indexes the order of columns in composite index is also of prime importance. For instance for the below customer table we have created an index with ‘customercode’ as the first column and ‘customerid’ as the second column.
If most of the SQL statements in your project are as shown below, i.e. with ‘customerid’ as the first column in the where clause then ‘customerid’ should be the first column in the composite index.
Select * from Customer where Customerid=1 and CustomerCode=9898998
If ‘customercode’ is the first column in the where clause as shown below then the composite key should have ‘customercode’ as the first column in your joint index key.
Select * from Customer where CustomerCode=9898998 and Customerid=1
What is the preferred data type for indexes?
‘integer’ data type is the preferred data type for indexes as compared to string data types like ‘char’ , ‘varchar’. If needed you can also choose ‘bigint’ , ‘smallint’ etc. Arithmetic searches are faster as compared to string searches.What are indexed views and how does it improve performance?
Indexed view is a virtual table which represents an output of a select statement. In general when we create a view the view does not store any data. So when we query a view it queries the underlying base table.
But when we create indexed views, result set is persisted on the hard disk which can save lot of overheads. So let’s understand advantages and disadvantages of indexed views.
Advantages
By creating indexed views you can store pre-computed values , expensive computations and join in the indexed views so that we do not need to recalculate them again and again.

Disadvantages
Indexed views are not suitable for tables which are highly transactional because SQL engine needs to also update indexed views if base table changes.
Can we see practically how indexed views increase performance?
Below is a simple query which calculates count as per ‘registerdate’ from the customers table. SELECT dbo.Customers.RegisterDate as RDate, count(*) as CountCust FROM dbo.Customers group by dbo.Customers.RegisterDate
In order to understand the same we will do the following:-
• We will run the above aggregate select query on the table without indexes and measure logical reads for the same. We will also measure logical reads for inserts on the same.
• In the next step we will create a clustered index and again record logical scan for select and insert.
• Finally we will create an indexed view and again measure logical scans for select and insert.

Benchmarking without indexes
So let’s fire the above aggregated statement without any indexes with statistics io on as shown in the below snippet.
Set statistics io on go SELECT dbo.Customers.RegisterDate as RDate, count(*) as CountCust FROM dbo.Customers group by dbo.Customers.RegisterDate
If you see the SQL plan it uses hash match.

The total logical reads for select query for the above operation is 16.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customers'. Scan count 1, logical reads 16, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
For insert the total logical read operation is 1.
set statistics io on insert into Customers values(429,'Shiv','1/1/2001') Table 'Customers'. Scan count 0, logical reads 1, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected)
Benchmarking with clustered indexes
Now let’s go and create a clustered index on the ‘customers’ table , set the statistics io on and see the plan. You can see that it uses the index scan and uses the stem aggregate logical operator to give the results.

The select query takes 10 logical reads to execute the above SQL query.
(6 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customers'. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
With clustered index insert takes 2 logical reads.
Table 'Customers'. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected)
Benchmarking with indexed views
Now let’s create an indexed view and try to benchmark again for select and insert queries. Below is the SQL snippet to create index views. Please note ‘count’ will not work with indexed views, we need to use ‘count_big’. Some function like ‘avg’ etc are also not allowed with indexed views.CREATE VIEW IndexedView WITH SCHEMABINDING as SELECT dbo.Customers.RegisterDate as RDate, COUNT_BIG(*) as CountCust FROM dbo.Customers group by dbo.Customers.RegisterDate GO CREATE UNIQUE CLUSTERED INDEX NonInx ON IndexedView(RDate); GO
If you see the plan you will see that there are no aggregate logical operators because it’s pre-calculated in the indexed views.

The select statistics show the logical reads as 1.
Table 'Customers'. Scan count 0, logical reads 1, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Insert logical scan is 18 for indexed views as shown below.
Table 'IndexedView'. Scan count 0, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 3, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customers'. Scan count 0, logical reads 1, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected)
So concluding indexed views are good for select aggregate queries they increase performance. On the other hand if your table is highly transactional then indexed views can decrease your performance.
Below is a simple performance impact graph which plotted using the above benchmark data. You can see how logical scan is decreased with select plus indexed views and how insert logical is increased with indexed views.

Performance is impacted in insert’s on indexed views because any updates to the base table needs to be also reflected back to indexed views which decreases performance.

Note: - If your base table is highly transaction indexed views will decrease performance of your insert, update and delete queries.
How do we specify index hints?
Does index hints increase performance?
References
• http://en.wikipedia.org/wiki/Query_plan • Execution plan basics by Grant FritChey http://www.simple-talk.com/sql/performance/execution-plan-basics/
• The best guide on logical and physical operators http://msdn.microsoft.com/en-us/library/ms191158.aspx
• Inside Microsoft SQL Server 2005: Query Tuning and Optimization by Kalen Delaney
Detail links which discuss Physical and logical read
• http://netindonesia.net/blogs/kasim.wirama/archive/2008/04/20/logical-and-physical-read-in-sql-server-performance.aspx • http://msdn.microsoft.com/en-us/library/aa224763(SQL.80).aspx
• http://msdn.microsoft.com/en-us/library/ms184361.aspx
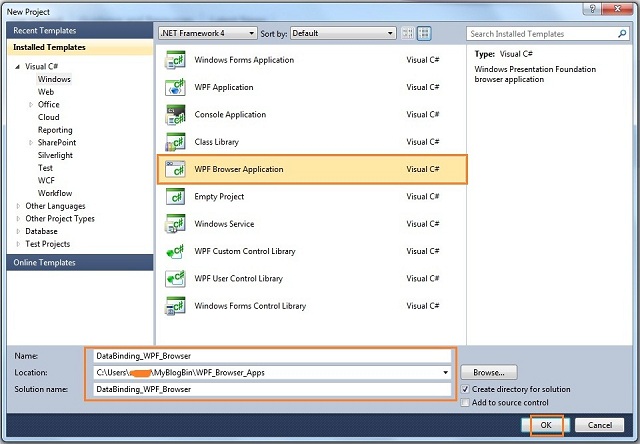 Select “Windows” --> Select “WPF Browser Application” and provide a name for the application, Click “Ok” to create a new WPF browser application.
Select “Windows” --> Select “WPF Browser Application” and provide a name for the application, Click “Ok” to create a new WPF browser application. 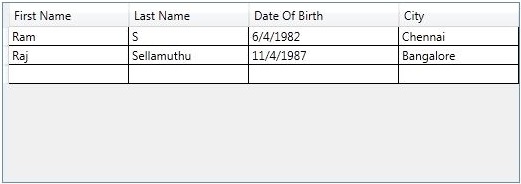 For the first column, I have used “
For the first column, I have used “ Right-Click on References --> Select “Add Reference”.
Right-Click on References --> Select “Add Reference”. 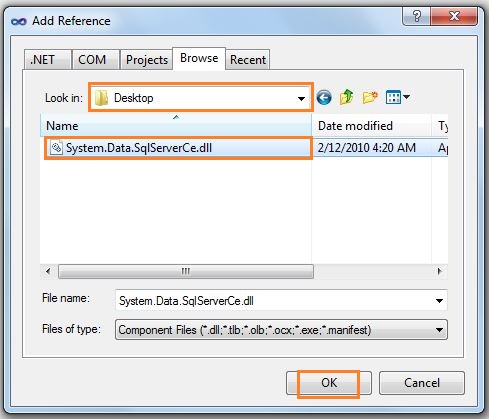 Browse to “C:\Program Files\Microsoft SQL Server Compact Edition\v3.5\Desktop” --> Select “System.Data.SqlServerCe.dll” and Click “Ok”. Now you can see “Sql Server Compact” listed in the references as shown below:
Browse to “C:\Program Files\Microsoft SQL Server Compact Edition\v3.5\Desktop” --> Select “System.Data.SqlServerCe.dll” and Click “Ok”. Now you can see “Sql Server Compact” listed in the references as shown below: 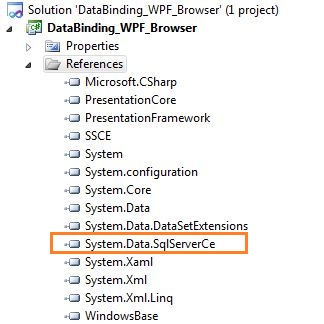 To use the methods of this namespace, call it in the header as we do for SQL Server.
To use the methods of this namespace, call it in the header as we do for SQL Server.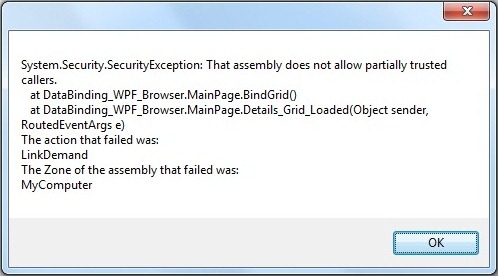 OOPs, I got the above error!!! (If you didn’t see this error and our project is executed … Wow .. you are lucky ;-)).
OOPs, I got the above error!!! (If you didn’t see this error and our project is executed … Wow .. you are lucky ;-)).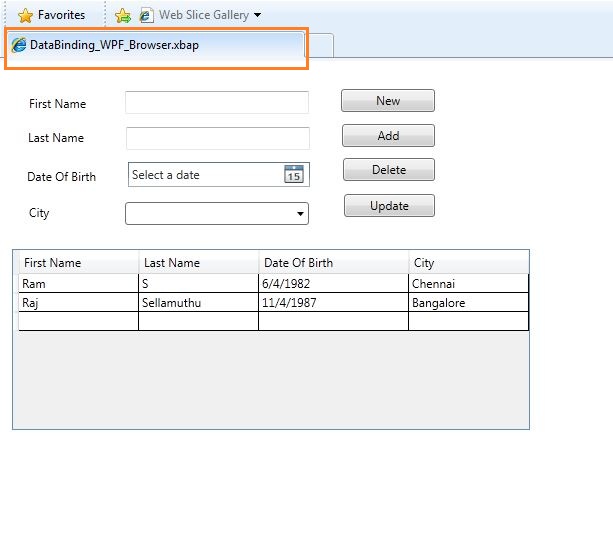 I found that browser title as “Databinding_WPF_Browser.xbap” which I want to change so I have added “
I found that browser title as “Databinding_WPF_Browser.xbap” which I want to change so I have added “ The browser title has been changed now :-) and I have tested the functionalities by adding, deleting and updating the data in the
The browser title has been changed now :-) and I have tested the functionalities by adding, deleting and updating the data in the